

不知要先进了多少倍,这个大家都容易理解。而对于大数据风控,其逻辑便在于“未来是过去的重复”,即用已经发生的行为模式和逻辑来预测未来。
统计学规律告诉我们,在实验条件不变的条件下,重复实验多次,随机事件的频率等于其概率。意味着,随着随机事件的大量发生,我们是可以发现其内在规律的。而大数据里面包含的海量数据,就为我们发觉隐藏在随机事件后面的规律提供了条件。
大数据风控的两个应用,信用风险和欺诈风险,背后都是这个逻辑,通过分析历史事件,找到其内在规律,建成模型,然后用新的数据去验证和进化这个模型。
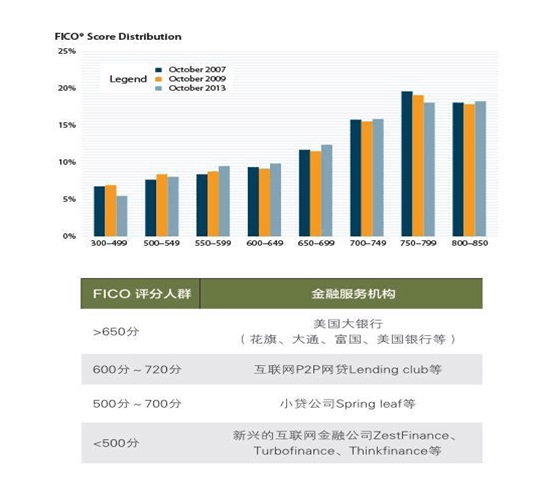
以美国主流的个人信用评分工具FICO信用分为例,FICO分的基本思路便是:

FICO评分是传统金融机构对大数据的运用,再来看看典型互金机构ZestFinance对大数据的运用,ZestFinance的客群主要就是FICO评分难以覆盖的人群,要么是在FICO得分过低金融机构拒绝放贷的人,要么是FICO得分适中,金融机构同意放贷但利率较高的人。
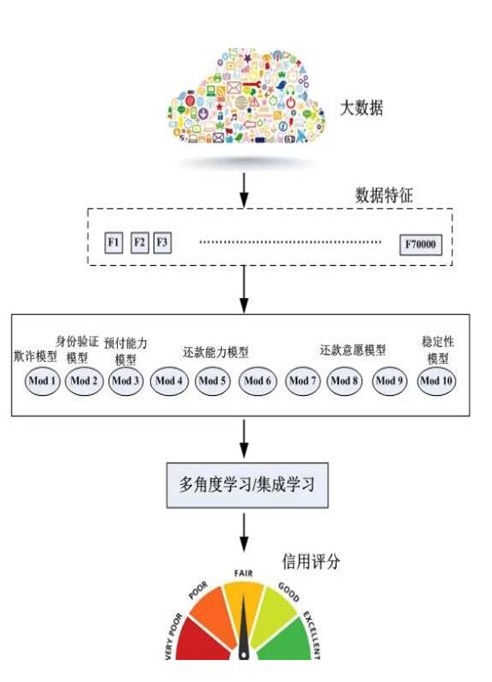
在ZestFinance的评分模型中,会大量应用到非征信数据(50%-70%左右),在其官方宣传中,提到会用到3500个数据项,从中提取70,000个变量,利用10个预测分析模型,如欺诈模型、身份验证模型、预付能力模型、还款能力模型、还款意息模型以及稳定性模型,进行集成学习或者多角度学习,并得到最终的消费者信用评分。
而欺诈风险的防控,本质上也是通过对历史欺诈行为的分析,不断梳理完善风险特征库,比如异地登录、非常用设备登录等行为,都是一种风险信号,建立一系列的风险规则判定集,预测用户行为背后的欺诈概率。
文:林健宇
图:林健宇

